
N64パーフェクトダークの日本語版では漢字のフォントが用意されていますが、ゲーム内では使用されなかった漢字について調査しました。
漢字リストの作成
過去に作成した漢字リスト
以前、ゲーム内テキストを変更する改造コードのために、文字コードを調査したことがあるのですが、そこで漢字を全て洗い出しました。
旧PD研究室の方に残骸が残っています。(早くこちらに移行したいですね)
http://pdlabo.knowhow.jp/kaizou/Dmojicode.php
※上記の漢字リストには誤りがあります。。最終的には修正することになります。
逆コンパイルソースコードの活用
海外のModコミュニティの方でも文字コードの解析はされていたのですが、さすがに漢字の部分は埋まりきっていなかったり、誤りがありました。
そこで私が調査した漢字リストを提供したりしていました。(この時点でもまだ誤りあり)
それからしばらくして、Ryan Dwyer氏による逆コンパイルによって、パーフェクトダークのソースコードが完成しました。
ソースコードは、GitLab上で公開されており確認することができます。
https://gitlab.com/ryandwyer/perfect-dark
詳しく知りたい方は、以下の記事をご覧ください。
ソースコード上では、ゲーム内テキストはjsonファイルで管理されています。
日本語もあるのですが、当初は漢字部分のほとんどは文字コードで定義されておりました。
例えば「src/assets/jpn-final/lang/mpmenu.json」というファイルでは、コンバット・シミュレータのメニュー上で使用されるテキストが定義されています。
テキストID「L_MPMENU_224」を見てみると「高速移動」なのですが「\\h83de\\h82ff\\h84a8\\h82c4」という文字コードで定義されていました。
まずはそのような部分を、全て漢字になるように僭越ながら修正させていただきました。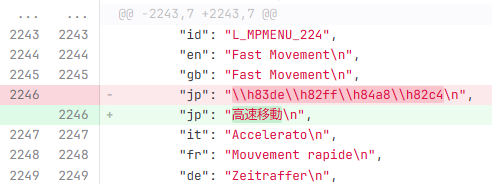
これにより、テキスト定義に漢字が含まれるようになったため、ゲーム内の日本語テキストの調査もできるようになりました。
例えば、以下は「データダイン地下研究所<探索>」のミッション説明文です。
このような感じで文章で読むことができます。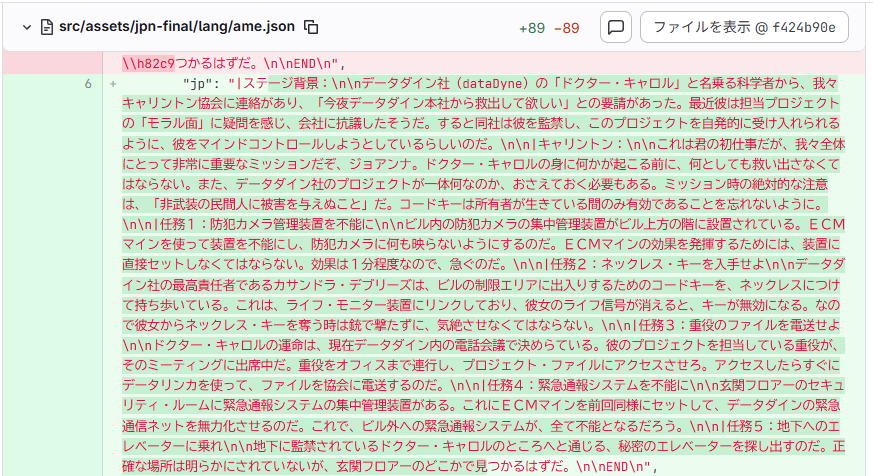
全体的に文章を読んでいくと一部漢字リストに間違いがあったことが判明したため全体的に見直し、修正しました。
以下に誤りがありました。
当時漢字を1個ずつメモしていたのですが、似たような字で見間違えていますねw熟語で見ると違いに気づけます。
- 浄→争(戦争の「争」)
- 九→丸(弾丸の「丸」)
- 逐→遂(遂行の「遂」)
- 艦→艇(探査艇の「艇」)
参考までに、私が修正したコミットは以下の3件です。
- https://gitlab.com/ryandwyer/perfect-dark/-/commit/f424b90eae4f2a3124fb666c3fb27c31feb43904
- https://gitlab.com/ryandwyer/perfect-dark/-/commit/577f97b8c80aff250a12752ea23cd6bf159fb253
- https://gitlab.com/ryandwyer/perfect-dark/-/commit/e1e6ace5ee8bb2e30134c803d644c4f4d0a20bb2
完成した漢字リスト
そんなこんなで完成した漢字リストが以下です。(「Character Codes」シート)
Perfect Dark Japanese Character Codes.xlsx (Google Drive)
未使用漢字の調査
完成した漢字リストを使って未使用漢字を調査しました。
Step 1:テキスト定義上に存在しない漢字を調査
全ての漢字をそれぞれテキスト定義に対して検索(grep)し、検索結果が0件となる漢字を洗い出します。
その結果、以下の20文字が洗い出せました。
偽犠牲偵察評価骸械襲登雷還恵恥論満仮振黒
Step 2:ゲーム内未使用テキストを調査
Step 1の調査では、あくまでテキスト定義上で未使用の漢字しか洗い出せておりません。
テキストの定義があってもゲーム内では未使用という場合もあります。
ゲーム内で未使用のテキストでしか使われていない漢字の場合は、未使用漢字となります。
調べ方としては、全てのテキストIDをそれぞれソースコード上で検索(grep)し、検索結果が0件となるテキストを洗い出します。
その結果は、以下の「Unused Texts」シートに記載しました。
Perfect Dark Japanese Character Codes.xlsx (Google Drive)
注意点としては、処理までは確認しておらず、分岐によって何かしらの条件でそこを通ることがなく、実質そのテキストは未使用というパターンが考えられるため、実は未使用のテキストが他にもある可能性があります。
また、テキストIDを動的に生成している箇所がありますが、全ては確認できていません。
1つ見つけたのは、シミュラントの名称や説明文、称号の名称の部分です。
テキストIDを動的に生成していたため、検索には引っ掛かりませんでしたが、ゲーム内では使用されているテキストのため除外しました。
Step 3:未使用テキストでしか使用されていない漢字を調査
ゲーム内で未使用テキストでしか使用されていない漢字を洗い出します。
調べ方としては、Step 1の調査を未使用テキストに対して実施し、件数を比較します。
すなわち、全ての漢字をそれぞれ未使用のテキスト定義に対して検索(grep)し、件数を出します。
Step 1で出した件数と上記で出した件数を比較して一致した場合、未使用テキストでしか使用されていない漢字ということになります。
その結果、1件のみ抽出されました。
月
lang/ame.json: "jp": "2023年8月15日 経過時間02:30\n",これはデータダイン本社<始動>の没データです。日付も考えられていたのでしょうか。
ただ、ジョアンナ・ダークの任務開始日については海外で考察されている方もいらっしゃって2023年5月5日という説もありますw
余談ですが、興味がある方はお調べください。
関係ないですが、パーフェクトダークの時代設定が2023年の近未来というのは凄いですね。
もう2025年ですが、開発されていた2000年頃から考えるとこのような未来が考えられていたのでしょうか。
まとめ
というわけで未使用漢字は以下の21文字でした。
偽犠牲偵察評価骸械襲登雷月還恵恥論満仮振黒
「偽」は、「大統領の偽者」のように使う予定だったのでしょうか。実際は大統領のクローンでしたね。
「犠牲」は使われていたような気もしたのですが、それはカタカナとなっており「ギセイ」でした。
アラスカ空軍基地<制圧>で多くの中立の民間人を倒すと「中立の人たちが多くギセイになった」というメッセージが出ます。
漢字だと潰れて読みづらいとか、読むのが難しいとか配慮があったのでしょうか。
「偵察」とか「評価」とかもありそうですが、意外と使われていないんですね。
「雷」はシカゴの説明文とかで使おうとしていたのでしょうか。
最後の「黒」は、元々日本語版のタイトルになりそうだった「赤と黒」のために追加された漢字だったのかもしれませんね。
文字コードの並びを見ると、87C9:赤、87CA:黒と連続しています。
ちなみに「赤」は使用されています。(赤い服の男、赤外線、赤い惑星など)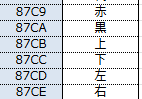
このように、なぜ未使用になったのか、何のために用意した漢字だったのかを考えるのも楽しいですね!
コメント